JPA
다들 프로젝트를 할 때 RDB와 접근하기 위해서 JPA를 접해보셨을겁니다.
JPA란 Java Persistence API의 약자로 ORM을 편리하게 사용할 수 있는 인터페이스입니다.
여기서 ORM이란 Object Relational Mapping으로 객체와 RDB를 자동으로 매핑해주는 것을 말합니다.
ORM은 보다 더 객체지향적인 코드를 사용할 수 있어 비즈니스 로직에 집중할 수 있고, 유지보수나 편리성을 증가시켜줍니다.
Hibernate
앞서 소개한 JPA의 구현체입니다. JPA 의 구현체는 더 있지만 가장 안정적인 구현체라고하네요.
JPA를 공부하다보면 JDBC라는 키워드를 많이 접해보셨을텐데요.
JDBC란 자바 DB 프로그래밍을 하기 위해 사용되는 API입니다.
JDBC는 직접 DB와의 Conn을 열고 닫아야하는 번거로움이 있을 뿐 아니라 반복적인 SQL을 사용하여 가독성을 떨어트려 요새는 조금 기피되는 기술입니다.
하지만 JDBC를 잘 알아야하는 이유는 JPA 내부에서 JDBC를 사용하고 있기 때문입니다. 따라서 JPA는 JDBC와 완전히 다른 개념은 아니다라는 것을 말씀드리고싶습니다.

Hibernate의 장점으로는 JPA의 구현체이다보니 ORM의 장점을 가져올 수 있습니다.
단점으로는 개발자 허들이 높습니다. 또한 ORM의 단점인 세부적인 SQL 작성은 어렵다는 점이 존재합니다.
Spring Data JPA
Spring Data JPA는 JPA를 편리하게 사용할 수 있게 만든 모듈입니다.
이전 Hibernate는 어찌보면 JDBC를 쉽게 활용하기 위한 인터페이스의 구현체이고
Spring Data JPA는 "JDBC를 쉽게 활용하기 위한 인터페이스" 를 쉽게 사용하기 위한 모듈인 셈이죠.
저희가 JPA를 사용하려면 EntityManager를 활용해 직접 EntityManager의 메서드를 활용해야하지만, 이를 추상화시킨 Repository 인터페이스를 제공해줍니다.
Tips.
Spring Data JPA에서 EntityManager를 활용한 인터페이스를 제공해주기 때문에, Service단에서 EntityManager를 다루는 것은 지양한다고 합니다.
Persistence
JPA를 공부하시다보면 또 하나 자주 접하는 개념이 있습니다. 바로 영속성에 대한 개념인데요.
영속성 컨텍스트(Persistentce Context)란?
구글에 검색해보시면 엔티티를 영구 저장하는 환경이라고 말합니다.
이 말만 들으면 감이 오지않으실텐데요. 캐시의 개념을 떠올리면서 다음 설명을 들어보세요.
저희가 Application을 사용하면서 DB와의 접근은 필수적입니다. 하지만 DB와의 I/O가 많아질수록 성능은 점점 떨어지고, 비용도 비싸집니다. 그럼 매번 쿼리가 있을때마다 DB에 가서 쿼리를 실행시킨다면 너무나 비효율적일 것입니다.
그렇기에 나온 개념이 영속성에관한 개념인데요.
영속성 컨텍스트는 마치 캐시처럼 가져왔던 정보를 저장하고있습니다. 언제는 가져왔던 정보를 개발자가 호출하면 DB에 가지않고 전해주기도하고, 또 언제는 쿼리를 모아놨다가 한꺼번에 DB에 적용시키기도하고, Update 쿼리를 날리지 않아도 변경감지를 해주기도합니다.
이렇게 설명하면 어떤 역할을 하는애구나 라는것은 이해하셨을것같은데요. 좀 더 자세하게 알아보도록 하겠습니다.
다음은 구글에 많이 돌아다니는 영속성 컨텍스트에 대한 사진입니다.

위에 보이시는 것과 같이 1차캐시가 존재합니다. 보통 Map형태로 만들어지며 (id값, entity) 가 들어가게됩니다.
JPA를 이용해 MemberRepository.findById() 를 사용하시면 첫번째로 1차캐시에 가서 해당 엔티티가 있는지 찾게됩니다.
만일 존재하지 않는다면 DB에 가서 찾게됩니다. 또한 DB에서 찾은 데이터를 1차캐시에 저장하게됩니다. 여기서 알 수 있는점은 캐시의 단점을 그대로 가져올 수 있는데요. 1차캐시에 데이터가 존재하지 않는다면 그냥 DB를 조회했을 때 보단 성능이 떨어지는 것을 알 수 있습니다.
JPA를 이용해 MemberRepository.save() 를 사용하시면 바로 DB에 데이터를 저장하지 않습니다. 조금은 개념이 흔들릴만한 말인데요. 그럼 언제 DB에 저장하는지가 궁금하실겁니다. 이를 이해하기위해선 Transaction에 대한 개념을 알고계셔야합니다. Transaction 링크의 글을 다 보고 오실필요는 없고 조금만 보고오셔도 무방합니다!!
그럼개념을 조금은 아신다 생각하고 글을 이어가겠습니다!
보통 Service Layer에서 Repository를 많이 다루실텐데요. Service Layer에서의 메서드의 CRUD 작업은 보통 Transaction으로 묶기 마련입니다. (Read 작업은 readOnly 옵션을 넣는것을 추천드립니다.) 그럼 해당 메서드 내의 로직은 하나의 Transaction으로 묶기는데 그전까지의 쿼리들을 모두 쓰기지연 SQL 저장소에 넣어두었다가 Transaction이 끝나면 한꺼번에 DB에 적용을 합니다. 이렇게되면 Transaction이 롤백되더라도 DB에는 적용이 안되어있으니 롤백하기 쉬워지겠죠. 또한 DB에 접근하는 시간을 줄일 수있겠죠.
마지막으로 변경감지를 알아보겠습니다.
해당 코드는 avatar 라는 엔티티를 DB에서 찾아오고 값을 변경하는 코드입니다.

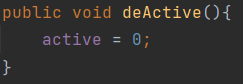
어디에도 save는 존재하지 않죠.

하지만 Update 쿼리가 잘 나갔네요? 이게 어떻게 된일 일까요?
앞서 말씀드린대로 영속성 컨텍스트는 변경감지를 하게됩니다. 영속화 되어있는 엔티티와 Transaction이 끝났을때의 엔티티를 비교하여 변경사항이 있다면 save를 하지않아도 반영이되는것이죠.
앞서 말씀드린 3가지 특징만 보더라도 영속성 컨텍스트가 가지는 편의성은 어마어마한데요. 하지만 조금 더 알아야될게 있습니다..
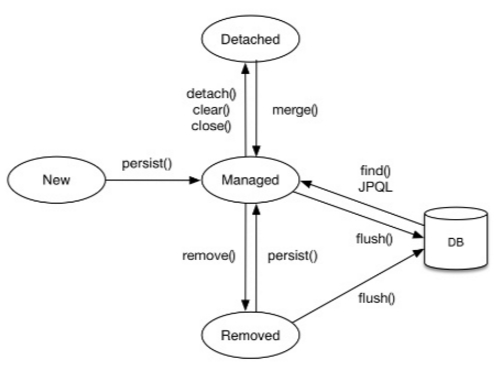
위 사진은 구글에 많이 돌아다니는 엔티의 생명주기 사진입니다.
엔티티는 다음과 같이 4가지 상태를 가지고있는데요.
- 비영속(new) : 영속성 컨텍스트와 전혀 관계가 없는 상태 (영속화를 한번도 거치지 않음)
- 영속(Managed) : 영속성 컨텍스트에 저장된 상태
- 준영속(detached) : 영속성 컨텍스트에 저장되었다가 나간상태
- 삭제(removed) : 엔티티가 삭제된 상태
위와 같이 4가지 상태를 가지고 있습니다.
비영속 상태는 Member member = new Member(); 와 같이 영속성 컨텍스트와는 전혀 관계가 없는 상태입니다.
이는 persist 또는 save와 같은 메서드를 통해 영속화를 시킬 수 있습니다.
여기서 잠깐!!
Q : 그럼 save와 persist의 차이가 뭐야?
save는 Repository에서 사용하는 메서드이고, persist는 EntityManager에서 사용하는 메서드입니다.
save는 영속화를 시키고 리턴값을 주는 대신, persist는 영속화만 시킵니다.
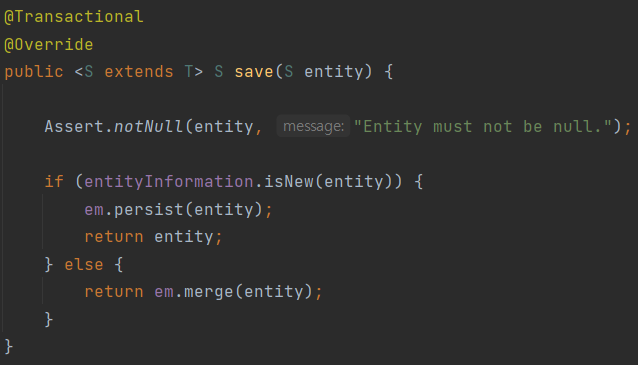
실제 SimpleJpaRepository 클래스의 save 메서드입니다. 보시면 persist 메서드를 그대로 사용하는것을 볼 수 있습니다.
영속 상태는 위와같은 방법으로 영속화된 엔티티의 상태입니다. 따라서 영속성 컨텍스트에 의해 관리됩니다.
준영속 상태는 영속성 컨텍스트가 지원하는 기능들을 사용하지 못하는 상태입니다. detach 메서드 혹은 트랜잭션이 끝났을때 해당 상태로 변하게 됩니다.
삭제 상태는 엔티티를 영속성 컨텍스트와 DB에서 삭제한 상태입니다. remove 메서드나 를 통해 delete 메서드를 통해 해당 상태로 변하게됩니다. 찾아보시면 아시겠지만 마찬가지로 Repository의 delete 메서드 내부에서 EntityManager의 remove 메서드를 사용하고 있습니다.
마지막으로 트랜잭션이 끝나기 전에 DB에 쿼리를 반영하고 싶을땐 어떻게 할까요?
그럴때 사용하는 것이 flush() 입니다.
EntityManager에 flush 메서드를 사용하면 가능한데, 아까 Tips으로 Service Layer에서 EntityManager를 다루는것을 지양한다고 했죠?
그럴땐 Repository에서도 flush를 할 수 있게 지원해주고 있습니다. 이를테면 saveAndFlush() 메서드를 말이죠!
JPA가 지원하는 쿼리방법들
JPA 다양한 쿼리사용 방법을 지원합니다.
그중에 가장 유명한 2가지를 소개하려하는데요. JPQL과 QueryDsl입니다!
일반적으로 기본키를 이용해서 단순하게 find하는 작업은 Repository가 제공하는 메서드를 이용하실텐데요.
좀 더 다양한 조건과 세부사항을 쿼리에 추가하기 위해 JPQL이나 QueryDSL을 사용합니다.
이 둘을 선택하는 기준은 정말애매한데 먼저 각각의 특징을 알아볼게요!!
QueryDSL
요새 가장 많이 쓰이는 쿼리인것 같은데요. 대표적인 장점으로는 다른쿼리들은 런타임으로 넘어가야만 아는 쿼리에대한 에러를 개발시에 알 수 있다는점입니다. 사실 QueryDSL 과 JPQL 을 비교한다곤 했지만, QueryDSL은 내부적으로 JPQL을 사용하고 있습니다!
그외에도 동적쿼리라면 QueryDSL을 선택하는데요. 이유는 BooleanExpression 을 이용해 쿼리를 한눈에 알 수 있게 만들 수 있기 때문입니다. 그외에도 다양하게 쿼리를 튜닝할 수 있는데 내용이 너무 많기에 그건 이동욱님 영상을 참고해주세요!
JPQL
딱히 QueryDSL과 비교했을 때, 장점이라고 할만한 특징을 말하기엔 애매한데요. 하지만 JPQL만의 특징은 존재합니다.
보통 단순한 쿼리는 QueryDSL을 사용하면 귀찮긴하기때문에 JPQL을 사용하시는 분들도 많습니다.
하지만 가장중요한 점은 JPQL과 영속성의 관계인데요.
JPQL이 작동하게되면 그전까지 영속성에서 관리되는 엔티티들을 모두 flush시키고, 그 후에 JPQL을 동작시킵니다.
여기서 주의할 점은 그 이후입니다. JPQL로 update 쿼리를 날린다면 그 이후 update 시킨 엔티티를 조회했을 때 변경이 적용되지 않을때도 있을겁니다.
JPQL은 update 쿼리를 날릴시 영속성에서 관리되는 엔티티들을 모두 flush시키고, 말 그대로 쿼리를 날리는 것이기 때문에 DB의 값을 변경시키고 작동이 끝납니다. 이때 일반 JPA 의 find의 동작방식대로 엔티티를 조회하면 영속성 컨텍스트에 있는 엔티티는 JPQL의 update 쿼리에 의해 변경이 되지않았으므로 변경되지 않은 엔티티를 조회해오는것이죠.
또한 JPQL의 find는 다른점이 있습니다. 보통은 영속성 컨텍스트를 먼저 조회 후 데이터가 없다면 DB를 조회하지만, JPQL은 DB를 먼저 조회 후 영속성 컨텍스트에 엔티티가 없다면 영속성 컨텍스트에 저장을 하고, 엔티티가 있다면 DB에서 가져온 값을 버리고, 영속성 컨텍스트에 저장되어있는 엔티티를 조회해옵니다.
이러한 JPQL의 특징을 잘 이해하고 있다면 좀 더 효율적인 쿼리를 작성할 수 있을 것 같습니다!
'Spring' 카테고리의 다른 글
| [Spring] WebSocket (0) | 2023.08.23 |
|---|---|
| [Spring] AOP (0) | 2023.06.08 |
| [Spring] Session (feat. 프로젝트 경험) (0) | 2023.04.28 |
| [Spring] application-{환경}.yml 과 @Value (0) | 2023.04.17 |
| [Spring] 단위 테스트 (0) | 2023.03.24 |



