스토리지 엔진
스토리지 엔진은 예를들어 InnoDB, MyISAM, Memory 등이 존재합니다.
사용자가 요청한 SQL 문을 토대로 DB 에 저장된 디스크나 메모리에서 필요한 데이터를 가져옵니다.
이후 해당 데이터를 MySQL 엔진으로 보내줍니다.
일반적으로 온라인상의 트랜잭션 발생으로 데이터를 처리하는 OnlineTractionProcessing 환경이 대다수이므로 InnoDB 엔진을 사용합니다.
MySQL 엔진
사용자가 요청한 SQL 문을 넘겨받은 뒤 SQL 검사를 하고 SQL 문을 최소단위로 분리하여 원하는 데이터를 빠르게 찾는 경로를 모색합니다.
이후 스토리지 엔진으로부터 전달받은 데이터 대상으로 불필요한 데이터를 제거하거나 가공하는 역할도 합니다.
파서
사용자가 요청한 SQL 문을 쪼개 최소단위로 분리하고 트리를 만듭니다. 트리를 만들면서 문법검사를 수행합니다.
전처리기
파서에서 생성한 트리를 토대로 SQL 문에 문제가 없는지 파악합니다. 또한 접근 권한은 부여되어있는지 이미 생성된 오브젝트인지 또한 확인합니다.
옵티마이저
전달된 파서 트리를 토대로 필요하지않은 조건은 제거합니다. 또한 어떤 순서로 테이블을 접근할건지, 인덱스를 사용할지 말지에 대한 계획을 정합니다.
단, 실행계획의 후보가 너무 많다면 계획을 선택하기까지 너무 많은 시간이 걸리므로, 모든 실행계획을 검사하진 않습니다.
이말은 옵티마이저가 선택한 실행계획이 최상의 실행계획이 아닐수도 있다는 것을 의미합니다.
엔진 실행기
옵티마이저에서 수립한 실행계획을 참고해 스토리지에서 데이터를 가져옵니다. 이후 MySQL 엔진에서는 읽어온 데이터를 정렬하거나 조인하고, 불필요한 데이터는 필터링하는 작업을 합니다.
서브쿼리
쿼리안에 보조쿼리를 가리키는 용어입니다.
서브쿼리는 3가지의 종류로 부를 수 있습니다.

스칼라 서브쿼리
select 절 안에 있는 또 다른 select 절이 스칼라 서브쿼리입니다.
메인 select 절에는 최종 출력하려는 열들이 나열됩니다. 따라서 출력 데이터 1건과 스칼라 서브쿼리의 결과 건수가 일치해야합니다. 또한 스칼라 서브쿼리는 출력되는 데이터 건수가 1건이어야하므로 집계함수가 자주쓰입니다.
인라인 뷰
메인쿼리의 FROM 절에 있는 서브쿼리를 인라인 뷰라고 말합니다.
일시적으로 뷰를 생성하여 해당 뷰에서 결과를 도출해냅니다.
중첩 서브쿼리
메인쿼리의 WHERE 절에 있는 서브쿼리를 중첩서브쿼리 라고 말합니다.
보통 IN, EXISTS, NOT 과같은 비교연산을 많이 사용합니다.
Join 알고리즘 용어
다수의 테이블을 조인할 때, 동시에 접근하진않으니 접근하는 우선순위를 정하곤합니다.
차례로 테이블을 접근하여 접근결과를 다음 테이블로 전달합니다.
이때 테이블에 접근하는 선후관계에따라 드라이빙 테이블과 드리븐 테이블이라는 용어로 분류될 수 있습니다.
드라이빙, 드리븐 테이블
앞서 언급한것처럼 드라이빙 테이블의 결과를 드리븐 테이블에 반환할텐데, 가능한 적은 결과가 반환 될것으로 예상되는 테이블을 드라이빙 테이블로 선정하는것이 중요합니다.
앞으로 설명드릴 상황에 대한 표준예시입니다.
중첩 루프조인
드라이빙 테이블의 데이터 1건당 드리븐 테이블을 반복해 검색하며 최종적으로는 양쪽 테이블에 공통된 데이터를 출력합니다.
블록 중첩 루프 조인
인덱스가 적용되지 않았다고 가정할 때, 극단적인 상황에서 중첩루프조인은 효율이 떨어지는데 이를 해결하고자 도입된것이 블록중첩 루프조인입니다.
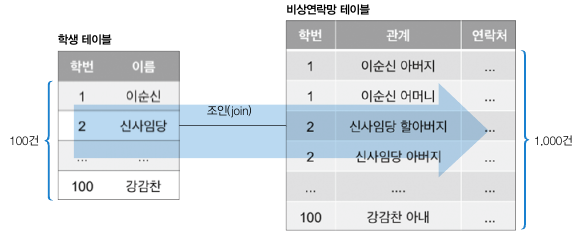
위에서 말한 극단적인 상황의 예시는 학번이 1, 100인 학생의 정보와 비상연락망을 가져오는 예시입니다.
먼저 학번 1 데이터를 찾기위해 학생테이블에서 100건의 조회를 하게됩니다. 그 후 동일한 데이터를 찾기위해 비상연락망 테이블에서 1000건의 조회를 하게됩니다.
이를 학번 100에서도 하게된다면 총 2200건의 조회를 하게됩니다.
블록중첩루프조인은 위와같은 상황에서 조인버퍼를 사용하여 효율적으로 상황을 개선합니다.
FTS 한번으로 학생테이블에서 원하는 학생정보를 모두 조인버퍼에 담습니다.
그 후 해당 버퍼와 비상연락망 테이블의 데이터를 비교하여 결과를 도출해냅니다.
배치 키 액세스 조인
중첩 루프조인방식에서 데이터 접근 시 인덱스에 의한 랜덤 엑세스가 발생합니다. 엑세스할 데이터의 범위가 넓다면 비효율적인 조인방식이므로, 접근할 데이터를 미리 예상하고 가져와 해당 문제를 해결하는 방법이 배치 키 액세스 조인입니다.
여기서 랜덤 액세스란 데이터를 저장하는 블록을 한번에 여러개 액세스하는 것이 아니라 한번에 하나의 블록만을 액세스하는 방식입니다. 따라서 한번에 여러개의 블록을 액세스 하는방식에 비해 성능이 좋지않습니다.
해시 조인
선후 관계를 두고 조인을 수행하는 중첩루프조인과는 달리, 조인에 참여하는 각 테이블의 데이터를 내부적으로 해시값으로 만들어 내부조인을 수행하는방식입니다. 해시값으로 내부조인을 수행한 결과는 조인버퍼에 저장됩니다.
오브젝트 스캔
테이블 풀 스캔
테이블을 처음부터 끝까지 훑어보는 방식입니다. WHERE 절의 조건을 기준으로 활용할 인덱스가 없을때 사용됩니다.
인덱스 범위 스캔
인덱스를 특정 범위만 스캔한 뒤 스캔 결과를 토대로 테이블의 데이터를 찾아갑니다.
BETWEEN ~ AND, LIKE 구문등 비교 연산에 포함될 경우 수행합니다.
좁은 범위를 스캔할때 효율적이고, 넓은 범위를 스캔할때는 비효율적입니다.
인덱스 풀 스캔
인덱스를 처음부터 끝까지 스캔하는방식입니다. 단, 테이블의 데이터를 요구하지않고 인덱스로 구성된 열 정보만 요구하는 SQL 일때 수행됩니다.
인덱스 고유 스캔
기본 키나 고유 인덱스로 테이블에 접근하는 방식입니다.
WHERE 절에 = 조건으로 작성합니다.
인덱스 루스 스캔
인덱스의 필요한 부분들만 고랄 스캔하는 방식입니다.
WHERE 절 조건문을 기준으로 필요한 데이터와 필요하지 않은 데이터를 구분한 뒤 불필요한 인덱스는 무시합니다.
시퀀셜 액세스
물리적으로 인접한 페이지를 차례대로 읽는 순차접근방식입니다.
테이블 풀 스캔에 보통 사용되고, 인접한 페이지를 여러개 읽는 다중 페이지 읽기방식으로 수행합니다.
랜덤 액세스
물리적으로 떨어진 페이지들에 임의로 접근하는 임의점근방식입니다.
다중 페이지 읽기가 불가능하기 때문에 데이터의 접근 수행시간이 오래걸립니다.
따라서 최소한의 페이지에 접근할 수 있도록 접근범위를 줄이고 효율적인 인덱스를 활용할 수 있도록 해야합니다.
조건 유형
WHERE 절 조건문을 기준으로 데이터가 저장된 디스크에 접근합니다.
액세스 조건
맨 처음 디스크에서 데이터를 검색하는 조건입니다.
옵티마이저는 WHERE 절의 조건문을 이용해 소량의 데이터를 가져오고, 인덱스를 통해 시간낭비를 줄이는 조건절을 선택합니다.
필터 조건
액세스 조건을 이용해 MySQL 엔진으로 가져온 데이터에서 불필요한 데이터를 제거하거나 가공하는 조건입니다.
필터 조건에서 다수의 데이터가 필터링되어 제거된다면 비효율적인 SQL 이므로 쿼리 튜닝이 필요할 수 있습니다.
응용 용어
선택도
테이블의 특정 열을 기준으로 해당 열의 조건절에 따라 선택되는 비율을 말합니다.
해당 열에 중복되는 데이터가 많다면 "선택도가 높다" 라고 표현할 수 있습니다.
즉, 낮은 선택도가 인텍스 열을 생성할 때 주요 고려대상이 됩니다.
선택도 = 1 / DISTINCT(COUNT 열명)
선택도를 위와 같은 수식으로 표현할 수 도있습니다.
선택도와 비슷하게 "전체 행에 대한 특정 열의 중복 수치"를 나타내는 "카디널리티" 라는 말 또한 존재합니다.
카디널리티는 중복되는 값이 적을때 "카디널리티가 높다" 라고 표현할 수 있습니다.
힌트
수 많은 데이터들 중 특정 데이터를 찾아내라는 문제를 마주했을 때, 힌트를 전달함으로써 빠르게 찾을 수 있게 도움을 주는 것입니다.
/*! */ 의 형태나 USE INDEX (~~) 의 형태로 명시할 수 있습니다.
하지만 옵티마이저는 무조건적으로 힌트를 참고하진 않습니다.
힌트가 적용된 환경에서 데이터 건수가 수시로 급변하거나, 인덱스/뷰에 변화가 생기면 SQL 실행 시 오류가 발샐할 가능성을 염두하여야합니다.
콜레이션
특정 문자 Set 으로 데이터베이스에 저장된 값을 비교하거나 정렬하는 작업의 규칙입니다.
예를들어 콜레이션 utf8_bin 과 utf8_general_ci의 환경을 비교했을 때 문자 a와 문자 A 중 대소관계가 달라질 수 있는 경우입니다.
통계정보
옵티마이저는 통계정보를 기반에 두고 SQL 실행계획을 수립합니다.
테이블 통계정보, 인덱스 통계정보, 선택적인 열 통계정보를 토대로 어떤 인덱스를 활용해 데이터 액세스를 할 것인지, 어떤 테이블을 드라이빙 테이블로 선택할지 등을 결정합니다.
따라서 통계정보의 최신성 유지가 매우 중요합니다.
히스토그램
테이블의 열값이 어떻게 분포되어 있는지를 확인하는 통계정보입니다.
● 참고자료 : 업무에 바로 쓰는 SQL 튜닝 (양바른 | 한빛미디어)
'DataBase' 카테고리의 다른 글
| [DataBase] Query 비교 및 개념 (0) | 2024.04.11 |
|---|---|
| [DataBase] DBCP (0) | 2024.04.11 |
| [DataBase] MySQL vs Oracle (0) | 2023.07.28 |
| [DataBase] 사용자 (0) | 2023.07.19 |
| [DataBase] MySQL 시스템 변수 (0) | 2023.07.18 |
